CRUXEval: Code Reasoning, Understanding, and Execution Evaluation

The code LM community primarily relies on benchmarks like HumanEval and MBPP, which test the ability to generate short code snippets from natural language specifications. Many efforts overfit to these benchmarks without necessarily improving other fundamentally important abilities of code models such as reasoning about code execution. When it comes to reasoning about code, GPT-4 still seems to have a huge edge over other models but still consistently fails on some surprisingly simple Python programs.
To better evaluate this aspect of code LMs, we design CRUXEval, a benchmark of 800 Python functions and input-output pairs. The benchmark consists of two tasks, CRUXEval-I (input prediction) and CRUXEval-O (output prediction) designed to evaluate code reasoning, understanding, and execution.
The benchmark was constructed as follows:
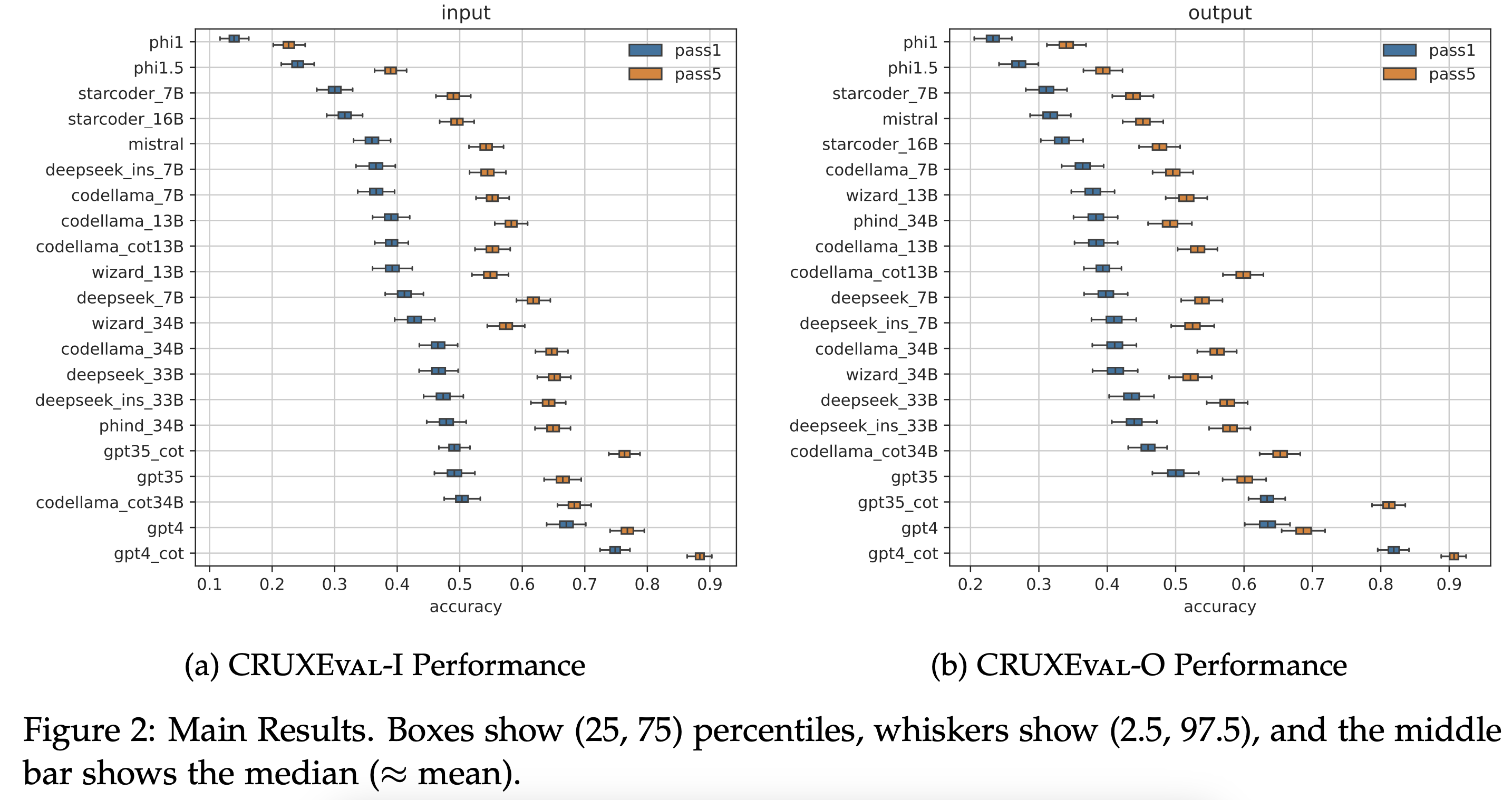
The best model, GPT-4, achieves a pass@1 of 67% on CRUXEval-I and 63% on CRUXEval-O, while widely used open-source models like Code Llama 34B only achieve 47% and 44%, respectively. Despite being trained on 100G of Python code and 1T of code data, it's a bit alarming that these models fail over half the time at simple execution prediction and code reasoning!
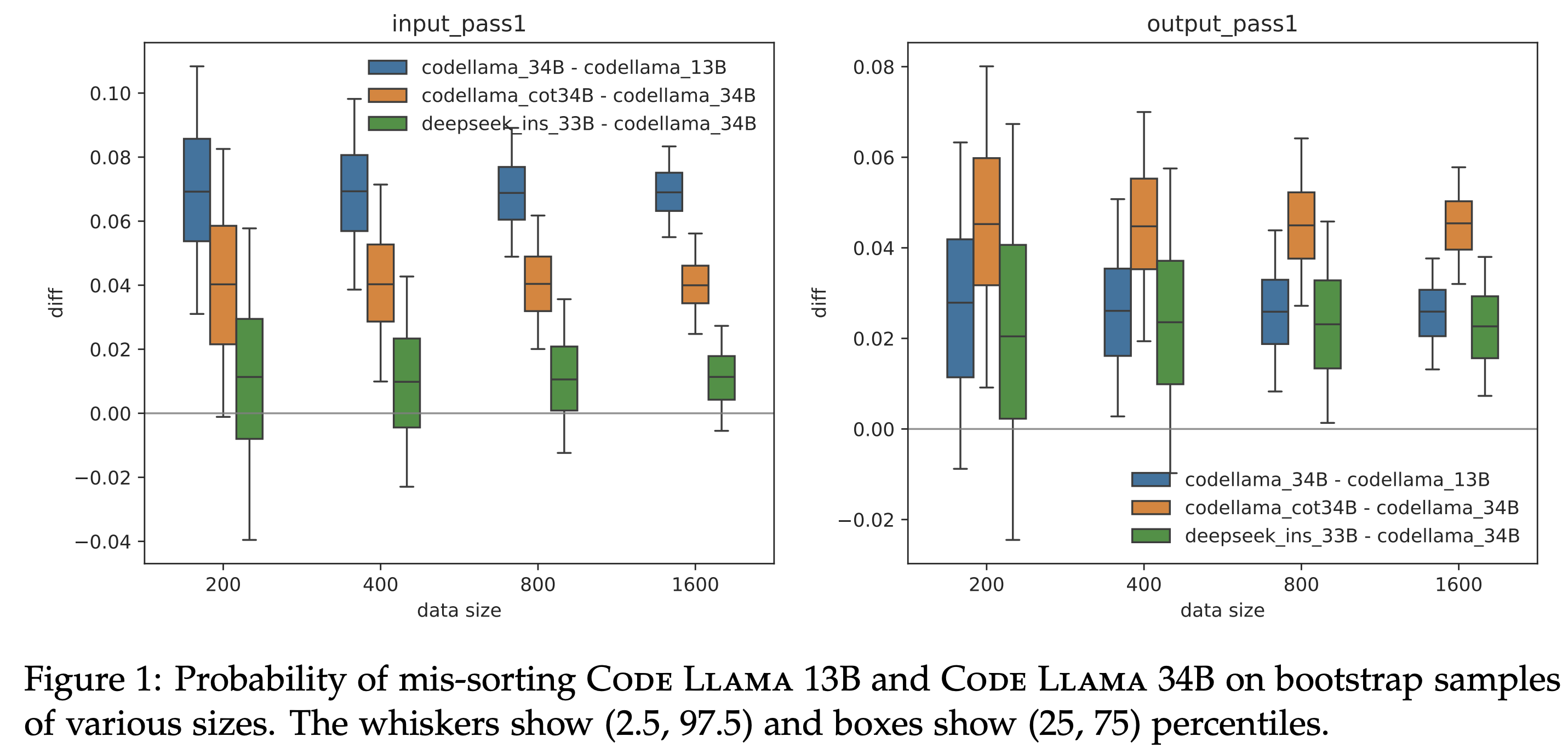
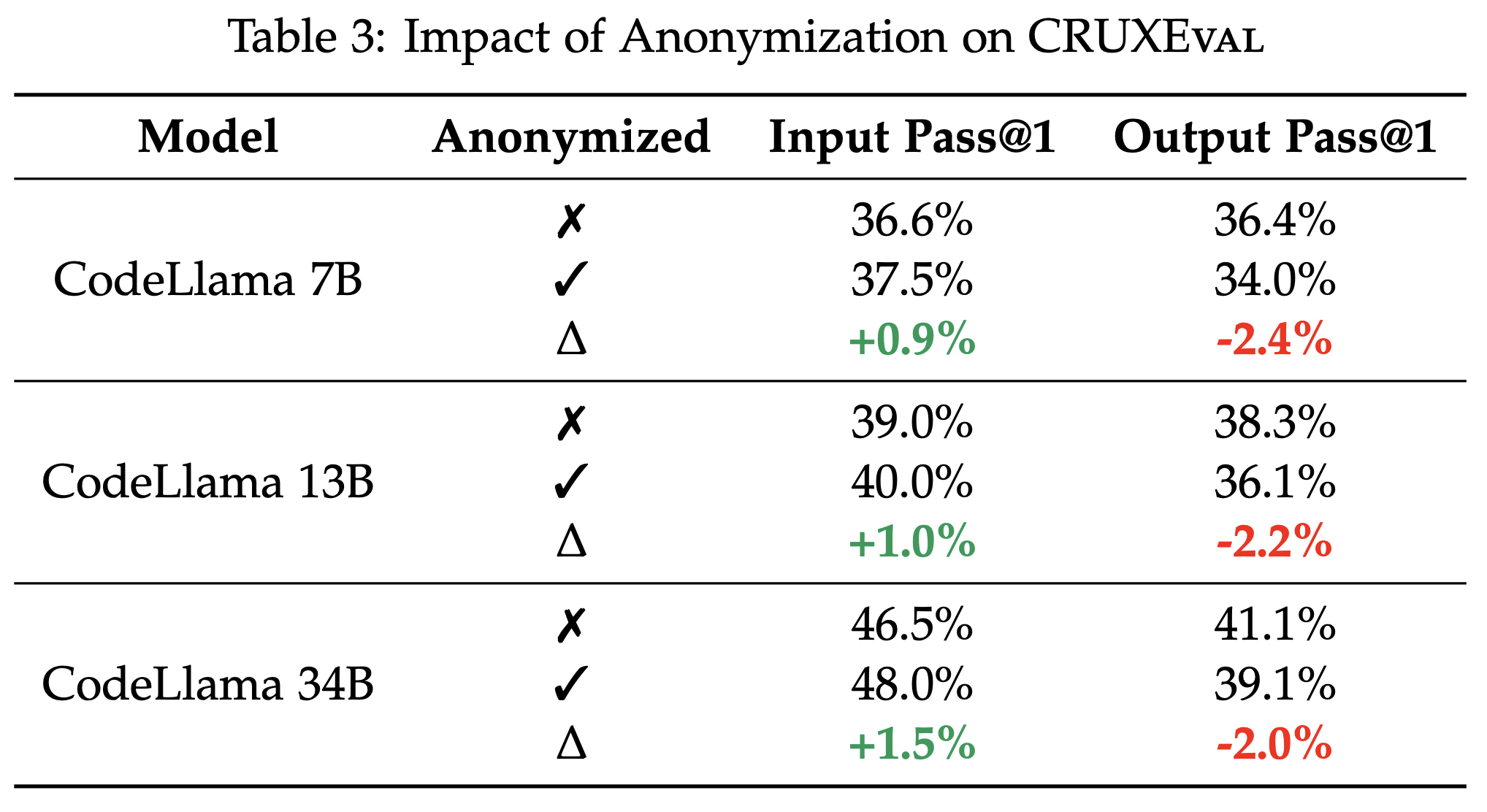
Another interesting result is that even when the variable names are replaced by placeholders like x1, x2, etc., performance on CRUXEval remains relatively similar (within 3%).
For base models, performance on HumanEval and CRUXEval are correlated. However, finetuning breaks this correlation: distilled models (WizardCoder, Phind, Phi) significantly beat their base models on HumanEval but not CRUXEval.
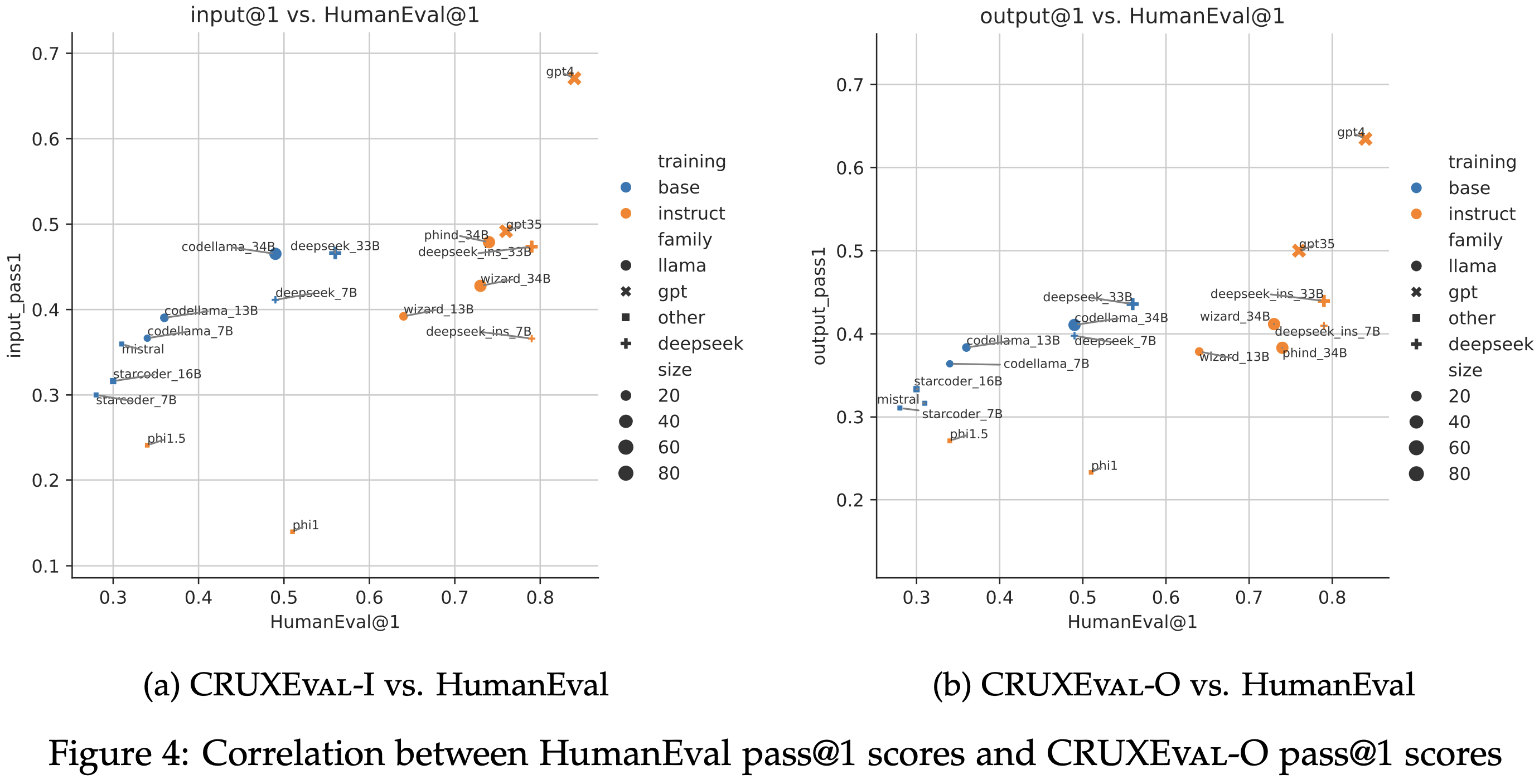
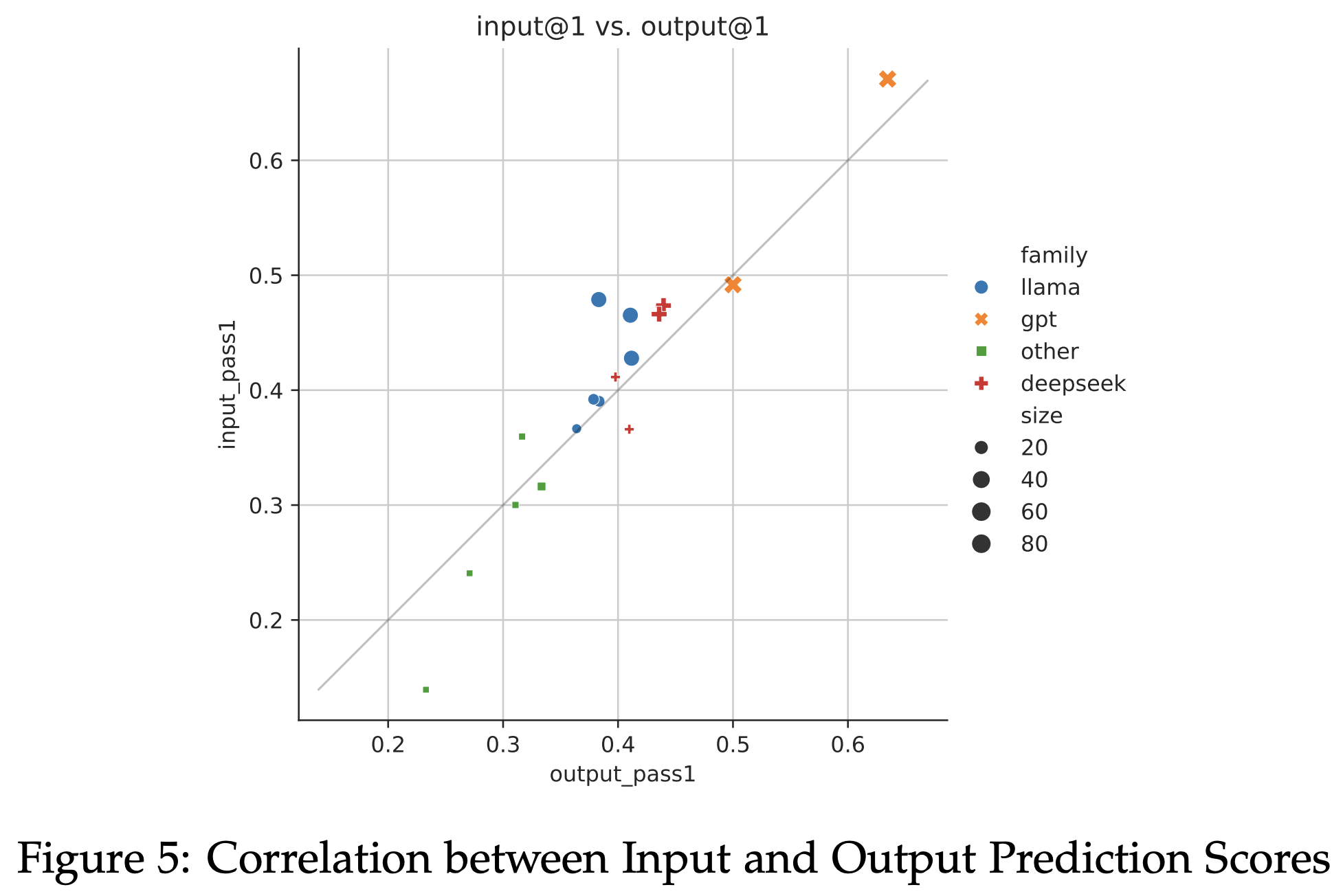
Performance on CRUXEval-I and CRUXEval-O are very correlated. Because the tasks seem relatively different, this suggests that the code reasoning capabilities of models may generalize across tasks.
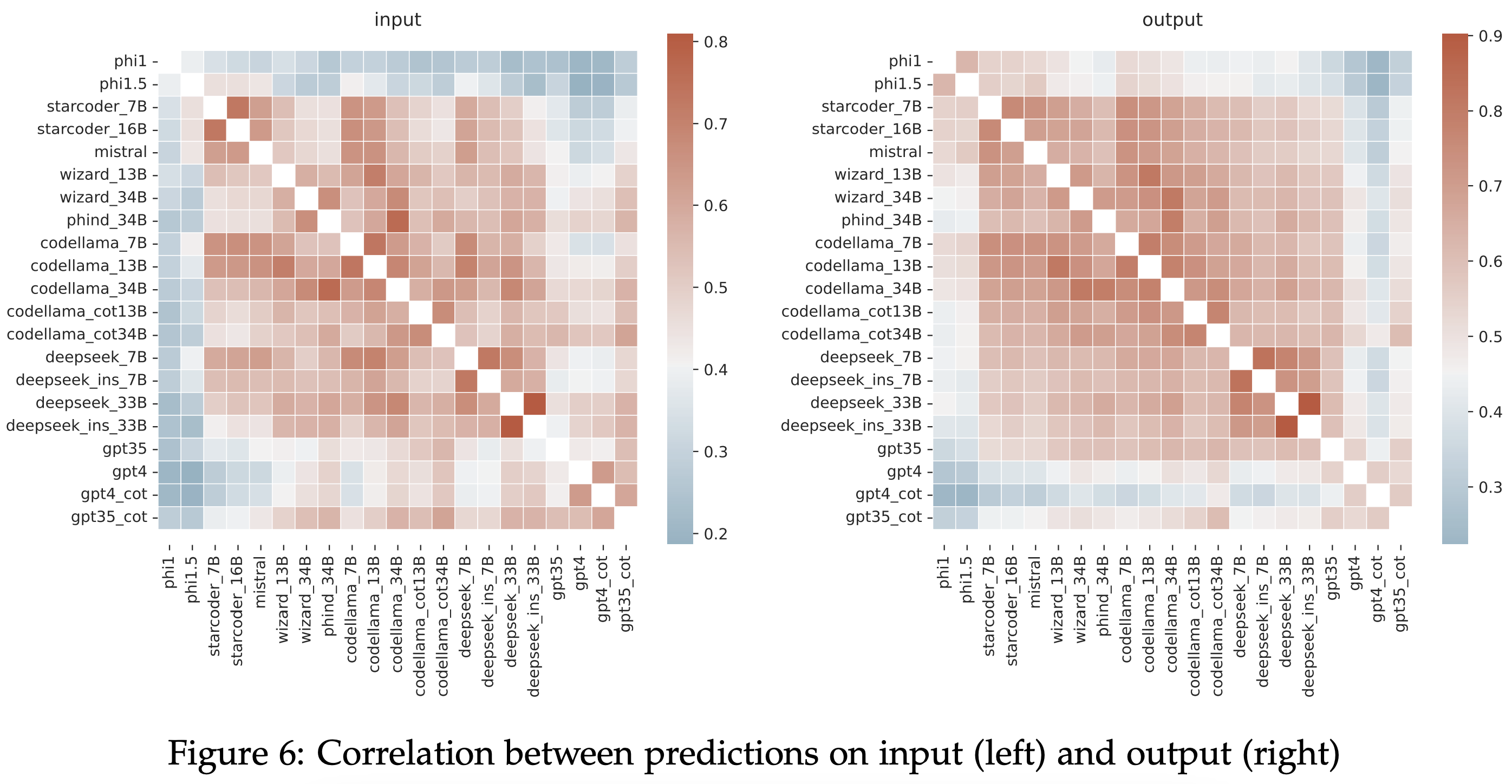
When comparing the predictions of different models, strong positive correlations are seen between sizes of the same model, between models of the same size, and between instruct and base models. On average, samples that are harder for one model tend to be harder for other models, but worse models succeed on some examples where better models fail completely, showing the idiosyncrasies of each model's failures.
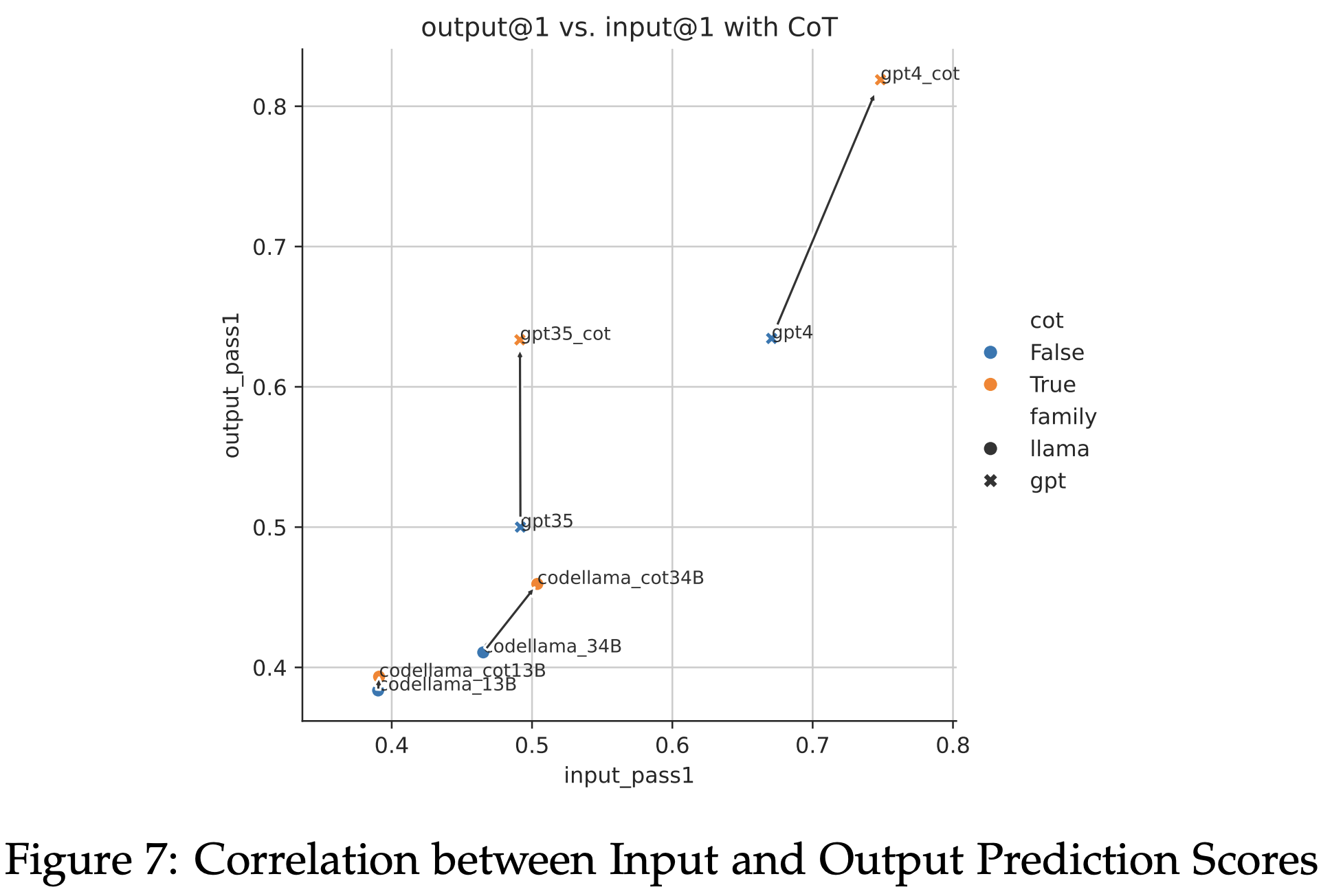
Using CoT led to some improvements, with larger boosts on output prediction than input prediction. GPT-4 benefits significantly more from CoT than other models, achieving the highest pass@1 of 74.8% on input prediction and 81.9% on output prediction.
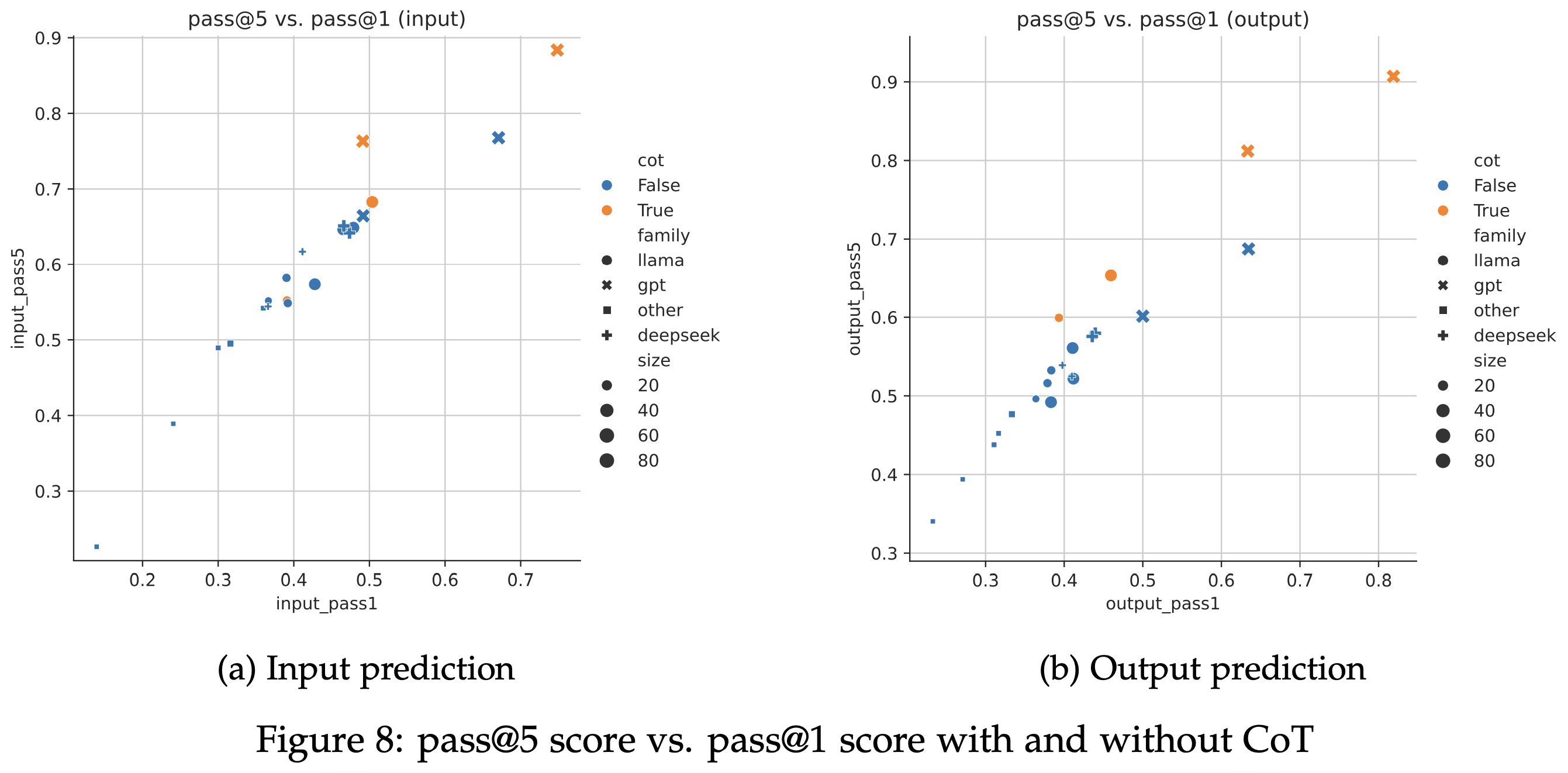
CoT increases the diversity of generated inputs and outputs, so models with CoT see a larger gap between pass@1 and pass@5 score compared to models without.
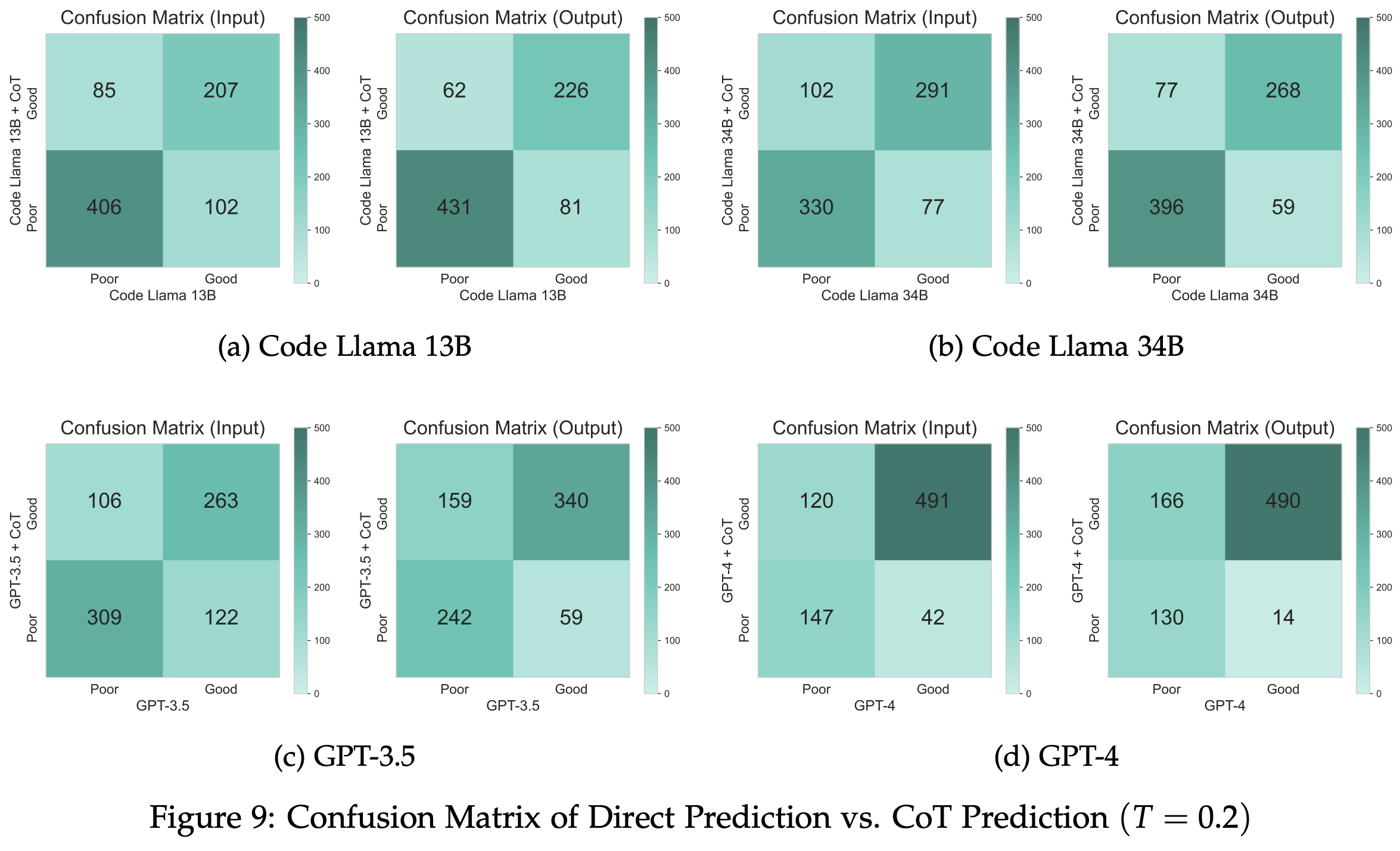
We also investigate the impact of CoT on individual samples. We classify a model's performance on an example as “poor” if the model gets that example wrong over half the time, and “good” otherwise. For Code Llama 13B/34B and GPT-3.5, we find many individual samples where CoT actually hurts the prediction accuracy. This is less the case for GPT-4, where CoT improves performance for most samples.
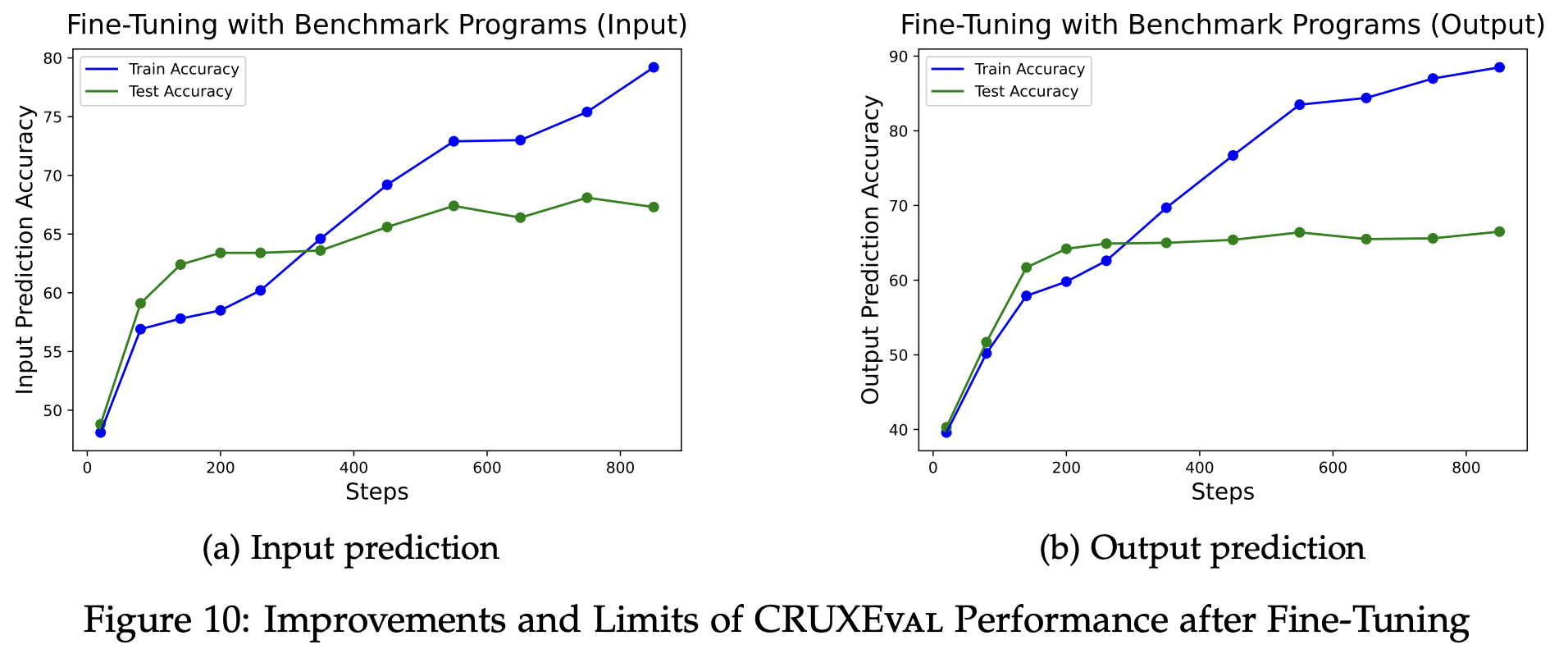
After fine-tuning Code Llama 34B on assertions very similar to those in our benchmark, it can match the performance of GPT-4 on both input and output prediction. However, accuracy plateaus at under 70% for both tasks, so simple finetuning is far from solving the benchmark.
While GPT-4 performs the best on our benchmark, we still find simple programs for which it fails to execute correctly even with CoT, such as the ones shown below.

Overall, we believe that CRUXEval provides a complementary perspective to classical code LM evaluations such as HumanEval and MBPP and encourage creators of future code LMs to evaluate on our benchmark!
@article{gu2024cruxeval,
title={CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution},
author={Alex Gu and Baptiste Rozière and Hugh Leather and Armando Solar-Lezama and Gabriel Synnaeve and Sida I. Wang},
year={2024},
journal = {arXiv preprint arXiv:2401.03065},
}